一位读者在蜘蛛抓取配额是什么这篇帖子留言:
不对呀,这个index标签,是指告诉蜘蛛可以抓取该页面,那么noindex不就是不允许抓取该页面吗?!那么为什么文章最后的几个说明里有“noindex标签不能节省抓取份额。搜索引擎要知道页面上有noindex标签,就得先抓取这个页面,所以并不节省抓取份额。”
留言说明,这位读者并没有太明白什么是抓取,什么是索引,index和noindex标签的意义又是什么。noindex标签不是不允许抓取该页面,是不允许索引该页面,这两者是不同的意思,有不同的功能。
看SEO有关博客和论坛时能感觉到,很多SEO并没有理解爬行、抓取、索引、收录这些概念到底指的是什么,区别在哪,noindex、nofollow、robots文件的功能又是什么。对这些概念没有精准理解,处理大型网站结构,决定什么页面需要被抓取,什么需要被索引,哪些页面需要禁止抓取、索引等等情况时,就很难明白该怎么做。甚至就像抓取配额那篇帖子的很多留言说的,提到这些情况的处理时,根本看不懂在说什么。
这么基本、重要,又比较容易混淆的SEO概念,我以为以前在博客里写过了,看了留言,翻翻以前帖子才知道,原来以前没写过。SEO实战密码书里是有写的,但SEO每天一贴里并没有写过。今天补上。
爬行是什么?
爬行指的是搜索引擎蜘蛛从已知页面上解析出链接指向的URL,然后沿着链接发现新页面(也就是链接指向的URL)的过程。当然,蜘蛛并不是发现新URL马上就爬过去抓取新页面,而是把发现的URL存放到待抓地址库中,蜘蛛按照一定顺序从地址库中提取要抓取的URL。
抓取是什么?
抓取是搜索引擎蜘蛛从待抓地址库中提取要抓的URL,访问这个URL,把读取的HTML代码存入数据库。蜘蛛的抓取就是像浏览器一样打开这个页面,和用户浏览器访问一样,也会在服务器原始日志中留下记录。
索引是什么?
索引指的是将一个URL的信息进行整理,存入数据库,也就是索引库,用户搜索时,搜索引擎从索引库中提取URL信息并排序展现出来。索引的英文是index。索引库是用于搜索的,所以被索引的URL是可以被用户搜索到的,没有被索引的URL用户在搜索结果中是看不到的。
要注意的是,所谓“一个URL的信息“,并不限于蜘蛛从URL上抓取来的内容,还有来自其它来源的信息,如外部链接、链接的锚文字等。有的时候,索引库中关于这个URL的的信息,根本没有从这个URL抓取来的内容,但搜索引擎知道这个URL的存在,并且有一些其它信息。
抓取和索引不是一回事。
收录是什么?
我个人觉得收录和索引没有区别。只不过收录是从搜索用户角度看的,搜索时能找到这个URL,就是这个URL被收录了。从搜索引擎角度看,URL被收录了,也就是这个URL的信息在索引库中存在。英文并没有收录这个词,和索引用的是同一个词index。
noindex的作用是什么?
页面头信息中放上meta noindex标签是告诉搜索引擎不要索引这个URL,也就是用户搜索时找不到这个URL的信息,这个URL不会返回在搜索结果列表中。
noindex不是告诉搜索引擎不要抓取这个URL,实际上,noindex要起作用,这个URL是必须先被抓取的,不然搜索引擎怎么看到页面HTML代码中有noindex标签呢?
robots文件的作用是什么?
robots文件是告诉搜索引擎,某些URL不要抓取。注意,这里说的是不要抓取,没说不要索引。和noindex是正相反的。
nofollow的作用是什么?
给链接加上nofollow属性是告诉搜索引擎,不要沿着这个链接爬行,就当这个链接不存在。注意,nofollow只是告诉蜘蛛不要爬这个链接,没有说不要抓取链接指向的URL,也没有说不要索引链接指向的URL,nofollow既没禁止抓取,也没禁止索引。
概念说过后,指出几个SEO们经常弄不明白的情况:
没有被抓取的页面是可以被索引的
也就是说,蜘蛛没有访问和抓取这个页面(比如被robots文件禁止抓取),这个页面却有信息存在索引库中,用户搜索时还能看到。
比如,淘宝整个网站用robots文件禁止百度蜘蛛抓取,但没有用noindex禁止索引(如上面说的,禁止抓取后,就没办法禁止索引了,不抓取,就看不到noindex标签了),所以即使百度没有访问和抓取淘宝页面,但淘宝很多页面是被百度索引的,用户可以搜到的:
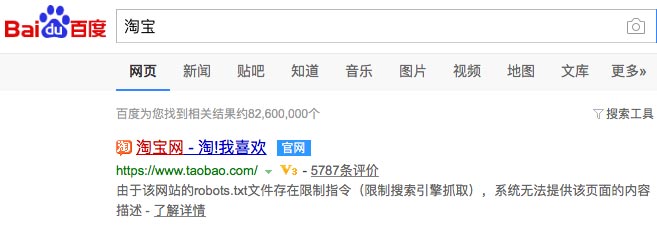
百度从网上那么多链接知道淘宝首页的存在,通过链接的锚文字也知道这个页面标题大概是淘宝之类的,当然更知道百度口碑里的评价数。所以即使百度蜘蛛没有抓取淘宝首页,用户还是能搜到,并且显示一些百度知道的信息。
要想百度不能返回淘宝首页该怎么办呢?取消robots文件的禁止抓取,页面上用noindex禁止索引。
被抓取的页面是可以不被索引的
最常见的就是上面说过的,页面头信息使用noindex禁止索引,页面被抓取,读到noindex后,不被索引,不会在搜索结果中返回。老页面新加noindex也不是马上删除索引,还会保留索引一段时间,但不会返回在搜索结果中。
加了noindex的页面上的链接是可以被跟踪一段时间的,但时间长了,有noindex的页面搜索引擎可能就不再抓取和索引了,上面的链接也就无效了。
还有可能是因为页面内容是抄袭、转载、低质量的,搜索引擎虽然抓取了页面,索引过程中检测出这些内容问题,被丢弃,没有被索引。所以页面没有被收录,通常要先检查原始日志,看看是否被抓取过,如果被抓取过,可能是内容质量问题,如果根本没被抓取,建议先看看网站结构是否有问题。
加了nofollow的链接目标页面可以被抓取和索引
前面说了,nofollow既不禁止抓取,也不禁止索引。nofollow的作用是告诉蜘蛛不要跟着这个链接爬,就当这个链接不存在,但nofollow只对这个链接起作用,对别的链接没作用,这个链接加了nofollow,不意味着别的地方就没有正常的指向这个URL的链接,只要别的地方出现了没加nofollow的链接,目标URL还是会被发现、抓取(假设没被robotx文件禁止)、索引(假设没加noindex )。
上面这些概念和应用在SEO中是很重要的,如果还没看懂,我也不知道该怎么再解释了,只能建议再多读几遍。
第一!!!!!!谢谢老师!
开始讲基础知识了?我是偶尔看看你写的文章,不是天天来,还好你也不是天天写!更新速度不快不慢,给读者建议,如果想学seo,没事就拿seozac的几篇文章和网站结构分析分析就ok了!其他的seo站太水,我的网站就是参考zac制作的!
我也是 看过zac大神的文章后就不愿意看别人的了 zac大神的文章通俗易懂 我以前什么都不懂 只看了两遍第三版seo实战密码就做了一个网站 请建站公司做的的 我不懂代码 但是所有的要求都是按照我自己的要求做的 现在优化了快五个月了,明显有转化率了 也开始接电话报价了 感谢zac
当时上线很仓促 建站五个月首页内页的标题改了二至三次 事实证明 新站频繁改标题是不会降权的今天刚换的服务器 第一个服务器被建站的坑了
接下来开始美化网站的图片
再次感谢zac大神 希望多多发些干货内容
借楼,谢谢!如果链接A被robots文件禁止了,那么B页面上的A链接蜘蛛还会爬行吗?
不会了,robots针对的是整个网站的链接;在多看几遍nofollow、robots和noindex的概念,差不多就理清思路了
如果一个网站的某个链接被nofollow,假设其他别的地方没有正常的指向这个URL的链接,那么是不是这个页面就一定不会被收录?
还有Zac老师说到nofollow会浪费权重,那么现在很多外贸网站用nofollow标签,是不是主要都是为了让更多的页面被收录而已?
要向你说这个假设,那这个页面肯定不会被爬行、更不会被抓取和索引!
第二个问题,可以再看下ZAC关于nofollow的帖子;
内部链接nofollow控制权重分布
https://www.seozac.com/onpage/internal-nofollow/
第一个关于nofollow收录的讨论,我自己网站的感觉是,google的比较容易收录nofollow的页面,哪怕自己没有去刻意为这些页面做非nofollow的链接;但是百度就很难去收录nofollow的页面,要过很久才会收录。
第二个问题,你贴的贴子是ZAC2008年的帖子,可以看他后来的更新,提到nofollow控制PR流动已经不管用了。
https://www.seozac.com/seo-news/seo-and-others/
除了你说的两个条件,还要加上你这个链接本身也是禁止蜘蛛爬行,禁止索引!
文章并没有说nofollow会浪费权重呀,相反的,如果nofollow禁止的是一些通往外部的链接,不访问,不是能更好的保证自身网站的权重吗?
爬行、抓取、索引、收录这些都比较易懂~老师今天是知识普及课^_^
最近一段时间感觉好多收录和索引增加都比较迟钝啊,不知道是个案还是普遍现象~
收录很重要,外链也是很重要,在SEO每天一贴学习到很多知识。
精辟
noindex标签以前没用过,谢谢老师分享!
seo已经不在第一页了。
基本的概念搞清楚以后,才会方便后续SEO优化工作的开展。
另外,想了解下,目前贵站从http转换成https版本之后,网站在百度的排名效果是否有明显提升?
今天还在看收录和索引的区别,看当到:百度的我个人觉得收录和索引没有区别。只不过收录是从搜索用户角度看的,搜索时能找到这个URL,就是这个URL被收录了。 我就放心了。我还以为我的网站内容出了问题~ 多谢zac
老师一如俱往的神采奕奕 文章还是那么实用干货 谢谢 看看我的网站老师评价下呗 http://www.bjqingyang.com
http://www.oakleysunglassesoutletshop.com/robots.txt 这个站的robots是全禁的 但是谷歌搜索出来 结果的描述并不会显示‘’此网站的内容由于robots限制而无法显示”,想问下老师 这种是怎么做到的
网站最近的权重掉的很厉害呀,SEO越来越难了
又算是复习了一下,因为之前就在《SEO实战密码》中学习过了,所以基本完全能够理解,不过这写东西确实有些绕,很多人如果从一开始没有分清楚,可能就会一直稀里糊涂的了吧!
谢谢分享,总结得很到位。
昝老师,看nofollow的时候有点要被绕晕的感觉。真得好好消化下,感觉做SEO这么久,还真的没把这些概念吃透。感谢昝老师,还愿意花这么多时间耐心讲解这些。受教啦!
Z神总是能把问题说的很清晰。
我的站不加www比加了www多了很多是什么原因呢?
写的很好很清晰,学习了。
这些都是很重要的关键词的认识。
不知道该怎么优化。。
你英语好 就可以随便拷贝国外文章吗?
我没有拷贝任何国外文章,这是我自己写的。照你这逻辑,中国人就不配说SEO,因为SEO是英语,外国人发明的,用了这个词就是抄袭啊。这是什么逻辑?
这篇文章新手必看,我是SEO的初学者,几乎每周都要看一看ZAC老师的博客,很受教,希望有一天和Zac老师能当面交流,久仰!
这些文章很有用,谢谢了
受教,谢谢Zac老师的好贴
刚开始做SEO,小白一个,多看看大神的博客,努力成长!
原来是这样!
Hello, zac老师! 有时间可否写写新站的外链建设相关的文章。不知道从哪里做起。也不知道频率应该是怎样。前期是否可以先做一些比较容易做,效果可能不会那么好的外链先积累着? 谢谢!!!!
新手,正在慢慢学习。这篇基础知识普及啊,看懂了
习惯了每次看文章的时候多反思自己所操作的。
受教了,谢谢
可能智商不足,之前一直对这些基础有点拎不清,弱弱的说一句:刚刚看了两遍帖子之后好像懂了。。。
SEO我还是个小白,关键词都没有几个 [泪] 还得好好研究啊!
受教了
非常感谢,很有帮助
这是在那个博客上发的
假如A和B两个产品页面重复,只是颜色区分。
然后B加入了noindex,A没加。
当然这里有个前提条件是都没有canonical标签。
权重会从B指向A吗?
不会
谢谢,我这里有一个网站从google search console下载了1000条收录的网址,其中有将近一半是带参数的网址是收录了,大部分都是产品页中带仓库,币种这样参数的网址,内容除了价格外,基本没什么区别,且这些网址外部几乎没有推广,我们都有加入了canonical标签指向不带参数的网址,但还是被收录了。
担心被分散太多的权重,所以我的想法是加入noindex这样的处理方式。但是这样又有两点担心:
1、没有达到canonical权重集中到某个产品的效果。
2、noindex,follow与noindex,nofollow从长远来看没有什么区别。这样权重还有多少传递到其他页面?
So in noindex and follow is essentially kind of the same as a noindex, nofollow. There’s no real big difference there in the long run.” John Muller, 2017
纠结啊。。。
如果说是robots文件设置不被抓取,是否是自然不被索引(前提网页没有被搜索引擎抓取过)
您好,问下bing的引擎搜我们官网就显示IP地址,也进不去,大神可以指点一二吗?